🌎 Historia del procesamiento de lenguaje natural
Primeras apariciones del procesamiento de lenguaje natural
Uno de los primeros problemas que intentó solucionar en NLP fueron los sistemas capaces de traducir textos de un idioma a otro.
Georgetown en 1964 fue uno de los primeros que utilizó un pequeño vocabulario junto a un conjunto de reglas simples para traducir frases del ruso al inglés.
Teoría de la gramática generativa
Esta teoría propuesta por Noam Chomsky introdujo la idea de una gramática universal subyacente a todos los idiomas humanos.
Durante esta época y al querer usar reglas universales, los sistemas que procesaban lenguaje natural se vieron con el desafío de capturar todas las sutilizas y excepciones del lenguaje natural.
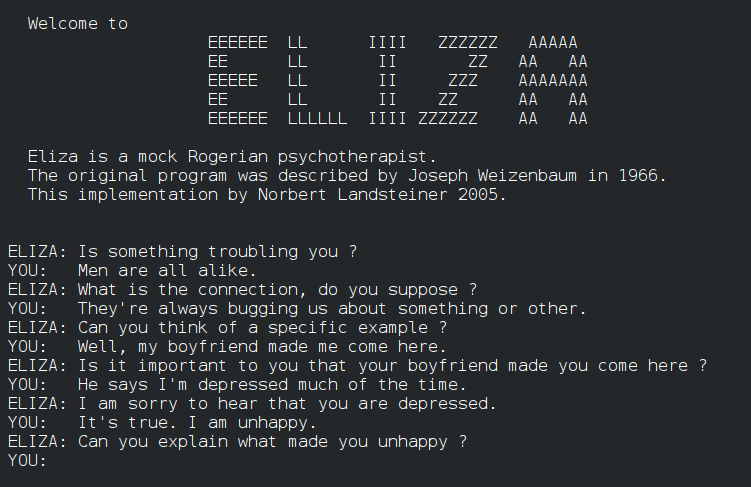
ELIZA y SHRDLU
Durante los años 60s y 70s, Joseph Weisenbaum diseñó ELIZA para simular una conversación. Este sistema podía adaptar diferentes roles, como el de un psicoterapeuta.
Del mismo modo, Terry Winograd creó SHRDLU, un sistema que permitía a las personas interactuar con un mundo virtual a base de simples comandos del lenguaje natural.

Ambos de estos sistemas estaban limitados a comprender realmente el lenguaje natural de las personas. Los sistemas sólo utilizaban interacciones predefinidas y con contextos muy específicos.
La ayuda de la inteligencia artificial al PLN
Como consecuencia de los avances de otras áreas de la inteligencia artificial como la representación de conocimiento y la comprensión semántica, se empezó a plantear que las computadoras sean capaces de entender el significado del lenguaje y no sólo su estructura.
Sin embargo, estos sistemas eran difíciles de escalar y requerían mucho trabajo manual para codificar el conocimiento del mundo.
Enfoques estadísticos
A finales de los 70s y a principios de los 80s, se empezaron a utilizar un enfoque estadístico para procesar lenguaje sin la necesidad de reglas rígidas, dándole la capacidad de aprender de grandes cantidades de datos.
Fue hasta la llegada del aprendizaje automático y el aumento del poder de cómputo, que fue cuando estos enfoques estadísticos tomaron vuelo y fueron plenamente aprovechados.
El procesamiento de lenguaje natural en la actualidad
Bidirectional Encoder Representations from Transformers (BERT)
Desarrollado por Google, es un sistema que introdujo un enfoque revolucionario en el preentrenamiento de representaciones lingüísticas. Esto permitió que el sistema comprendiera el significado de una palabra con base a su relación con las demás palabras en la oración. Esto mejoró en gran medida la comprensión de lenguaje, ayudando a las tareas de clasificación de texto y la respuesta a preguntas.

Generative pre-trained transformer (GPT) de OpenAI
Todo empezó con GPT-1 en 2018, que mejoró los niveles de la generación de texto en temas de fluidez y coherencia. GPT-2 y GPT-3 aumentaron el número de parámetros, permitiendo que el texto sea casi indistinguible al texto escrito por humanos. GPT-4 mejoró la comprensión de textos complejos y su capacidad de interactuar en modalidades multimodales. De igual manera, este modelo puede utilizar imágenes y generar texto a partir de ellas.
Todos estos avances han permitido enriquecer y eliminar las barreras entre la interacción de las personas y las computadoras. Permitiendo que las máquinas puedan comprender y responder de manera coherente, más allá del texto tradicional.
